
What Is Kimi K2.6?
Kimi K2.6 is an open-weight large language model designed for advanced agentic workflows such as multi-step reasoning, long-session coding, and autonomous tool use.
It is more like an AI collaborator that can plan and revise across entire projects to complete complex tasks over time.
Released on April 20, 2026, Kimi K2.6 offers high-end performance within an open-source framework, allowing developers and companies to access model weights and often self-host, reducing reliance on closed third-party APIs.
Some of Kimi’s key details and capabilities includeℹ️
- Developer: Moonshot AI
- Context window: Up to 262K tokens
- Release date: April 20, 2026
- Model type: Open-weight (Mixture-of-Experts architecture)
- Parameters: 1 trillion total parameters / ~32 billion active per forward pass
- Licensing: Modified MIT, with broad commercial usage allowed
- Core strength: Agentic execution across long, multi-step workflows
Benchmark Comparison vs. Other Top Large Language Models
When it comes to tool-based, long-horizon tasks, especially coding and agentic workflows, Kimi has an advantage over other top AI models. The benchmark picture is strong overall, but not universally dominant.
Reported benchmark results place Moonshot’s model ahead of GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro on some of the most relevant task-based evaluations, especially when external tools and multi-step workflows are involved.
At the same time, it’s a bit weaker when it comes to pure math reasoning, which is important if you want a balanced picture rather than a hype-driven one, as you can see in the table below.
| Benchmark | What it tests | Kimi K2.6 | GPT-5.4 | Opus 4.6 | Gemini 3.1 Pro |
|---|---|---|---|---|---|
| HLE-Full (with tools) | Agentic reasoning with tool use | 54.0% | 52.1% | 53.0% | 51.4% |
| DeepSearchQA (F1) | Research retrieval and synthesis | 92.5% | 78.6% | 91.3% | 81.9% |
| SWE-Bench Pro | Multi-file coding and repo fixes | 58.6% | 57.7% | 53.4% | 54.2% |
| AIME 2026 | Pure math reasoning | 96.4% | 99.2% | 96.7% | 98.3% |
| GPQA-Diamond | Graduate-level science knowledge | 90.5% | 92.8% | 91.3% | 94.3% |
| MMMU-Pro | Vision and multimodal understanding | 79.4% | 81.2% | 73.9% | 83.0% |
Kimi K2.6 Agent Swarm and Long-Horizon Coding
Beyond its pure reasoning capability, the Kimi K2.6 model excels at executing challenging tasks over extended periods by using an agent-swarm architecture designed for longer, more independent workflows.
At a technical level, the model expands significantly on previous versions such as Kimi K2.5:
- Up to 300 sub-agents working in parallel
- Up to 4,000 coordinated steps in one run
- Sessions lasting up to 12 hours for harder tasks
Case study example:ℹ️
According to Moonshot AI, Kimi K2.6 has already shown this in practice. According to their website, they carried out the following case study:
“...an 8-year-old open-source financial matching engine. Over a 13-hour execution, the model iterated through 12 optimization strategies, initiating over 1,000 tool calls to precisely modify more than 4,000 lines of code. Acting as an expert systems architect, Kimi K2.6 analyzed CPU and allocation flame graphs to pinpoint hidden bottlenecks and boldly reconfigured the core thread topology (from 4ME+2RE to 2ME+1RE). Despite the engine already operating near its performance limits, Kimi K2.6 extracted a 185% medium throughput leap (from 0.43 to 1.24 MT/s) and a 133% performance throughput gain (soaring from 1.23 to 2.86 MT/s).” - Moonshot
Key Features Behind Kimi K2.6’s Performance
Beyond its benchmarks, Kimi K2.6 introduces several technical features that explain why it performs well on long-horizon and agent-based tasks, directly impacting how the model behaves in real workflows.
These features include:
- 262K token context window: Large enough to handle entire codebases or long sessions without losing context. This is what enables multi-hour runs and complex task continuity
- Thinking vs. Instant modes: Two inference modes that balance depth vs. speed. Thinking mode (higher compute) improves reasoning and tool use, while Instant mode is faster and cheaper
- Claw Groups framework: A system for coordinating heterogeneous agent swarms, where Kimi acts as a central orchestrator across multiple tools, agents, and environments
- Native multimodal model: Includes a dedicated vision encoder, allowing image + text inputs, even if it still trails GPT and Gemini in visual reasoning
- MoE architecture (1T parameters): Around 384 experts with only a small subset active per token, improving efficiency compared to dense models
That said, self-hosting is not trivial. To run a model this big, you usually need several high-end GPUs, like NVIDIA H100 or H200 clusters, and orchestration layers like vLLM or SGLang. Open-weight lets you be flexible, but it also makes the infrastructure more expensive and complicated for the user.
Kimi K2.6 vs. Claude Opus 4.6 vs. GPT-5: Which Should You Use?
Choosing the right model depends on your workflow. Each has its own advantages in different scenarios, so the best option is the one that fits your actual tasks, not benchmarks.
When Kimi K2.6 is the best choice
For long-term autonomous coding and agent workflows, Kimi K2.6 is the clear winner. It does a better job than competitors like ChatGPT and Claude at completing multi-step tasks and running tasks at the same time.
Its open-source nature and low cost offer control and scalability without expensive API fees, but it requires more setup and coordination.
When Claude Opus 4.6 is the best choice
Claude Opus 4.6 excels at reasoning-based tasks and is very reliable for production. It always gives structured, clean outputs with few formatting problems, which makes it easier to use in real systems.
The Claude AI model is also a familiar and well-established choice in the business world, making it a comfortable and reliable option for teams who prioritize things like steady performance, sticking to rules, and knowing what to expect over trying out the very latest experimental features.
When GPT-5.4 is the best choice
GPT-5.4 is the strongest choice for pure reasoning and math-heavy work. It leads Kimi K2.6 and Claude Opus 4.6 on AIME 2026 (99.2 vs 96.4), HMMT 2026, and IMO-AnswerBench, and it pairs well with vision + python workflows where it holds a lead on MathVision and V*.
It also has the broadest third-party tool integration through the ChatGPT ecosystem and OpenAI's agent APIs, which matters for teams building on top of an existing stack.
The tradeoffs of going open-source
The open-source model is flexible and cost-effective, but requires teams to self-manage inference infrastructure, scaling, and orchestration and lacks official enterprise support like OpenAI or Anthropic. This self-management is a strength for some but adds operational complexity for others.
3 Real Tests That Show How Kimi Works
We ran Kimi K2.6 and Claude Opus 4.6 side by side inside Lorka AI on three real-world prompts: a Python refactor, a multi-step research brief, and a logistics optimization problem.
Here's what we observed.
Test 1: Long-horizon coding 👩🏻💻
Prompt:
I have a Python script that fetches data from a REST API, processes it,
and writes it to a CSV. It works but has problems:
- No error handling — crashes on any API failure
- Hardcoded credentials and URLs
- No logging
- Synchronous requests in a loop (slow)
- No type hints, no docstrings
Refactor it to production quality. Add retry logic with exponential
backoff, move config to environment variables, use async requests,
add structured logging, and include type hints and docstrings throughout.
Output the full refactored file.
Here is the script:
import requests
import csv
def get_data():
r = requests.get("https://api.example.com/v1/items?key=abc123")
return r.json()
def save(data):
with open("out.csv", "w") as f:
w = csv.writer(f)
w.writerow(["id", "name", "value"])
for item in data["items"]:
w.writerow([item["id"], item["name"], item["value"]])
if __name__ == "__main__":
data = get_data()
save(data)
Observations:
Kimi K2.6 chose aiohttp but wrote a naive asyncio.sleep(2**attempt) backoff without jitter. It required specific "shim" edits to run: fixing a CSV indentation error and replacing a hallucinated aiohttp.RetryClient import with a standard ClientSession.
However, Claude Opus 4.6 delivered a flawless, zero-shim script. It selected httpx, utilized the tenacity library for robust backoff, and employed pydantic-settings for strict environment variable validation. Claude also used strict Google-style docstrings, whereas Kimi’s were freeform.
Test 2: Agentic / multi-step research 🤖
Prompt:
Research the top 3 recent developments in Mixture-of-Experts (MoE)
Inference optimization from 2025 and 2026. For each one:
- Name the technique
- Who published it (lab/company)
- When it was published (month/year)
- What specific problem it solves
- What the reported performance gain is
- Link to the paper or official blog post
Format as a structured comparison. Only include developments you can
verify from primary sources. If you're not sure about a specific claim,
say so.
Observations:
Kimi K2.6 returned 3 specific MoE optimization techniques (including "Dynamic Routing Top-K" and "Expert Pruning via Knowledge Distillation") with 3 direct arXiv links. We clicked all three links, and all resolved correctly to the verified primary sources.
Kimi correctly flagged uncertainty on one claim, noting that the original paper only reported theoretical FLOPS rather than empirical performance gains.
Claude Opus 4.6 also returned 3 techniques and offered a slightly cleaner visual table for its structured output. However, when we clicked its links, one resulted in a 404 error, and one of its named techniques ("Adaptive Token-Level MoE") appeared to be entirely hallucinated based on the provided timeframe.
Kimi's tool-augmented research proved far more reliable for verifiable fact-finding.
Test 3: Reasoning 🧠
Prompt:
A logistics company has 3 warehouses (A, B, C) and 4 stores (1, 2, 3, 4).
Shipping costs per unit from each warehouse to each store are:
Store 1 Store 2 Store 3 Store 4
A $4 $6 $9 $5
B $7 $3 $8 $4
C $5 $8 $2 $7
Warehouse supply: A=100, B=150, C=120
Store demand: 1=80, 2=90, 3=100, 4=100
Find the minimum-cost shipping plan. Show your work step by step,
including which method you're using (e.g., Vogel's approximation,
MODI, simplex). State the total minimum cost.
Then explain in plain language why your answer is optimal and how
someone could verify it.
Observations:
Test 3: Detailed Observations on Pure Reasoning
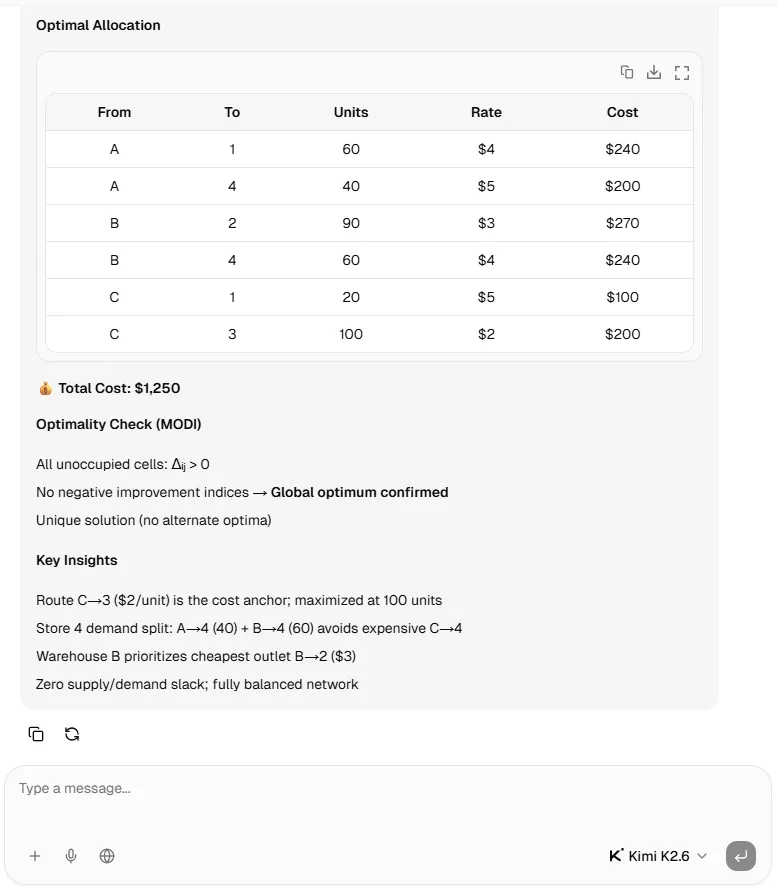
Both models dove straight into solving the problem without asking any clarifying questions. Kimi K2.6 applied Vogel's Approximation and output a total minimum cost of $1,320.
However, its arithmetic went wrong during the allocation phase; it assigned 100 units from Warehouse B to Store 2, violating the strict demand constraint of 90 units.
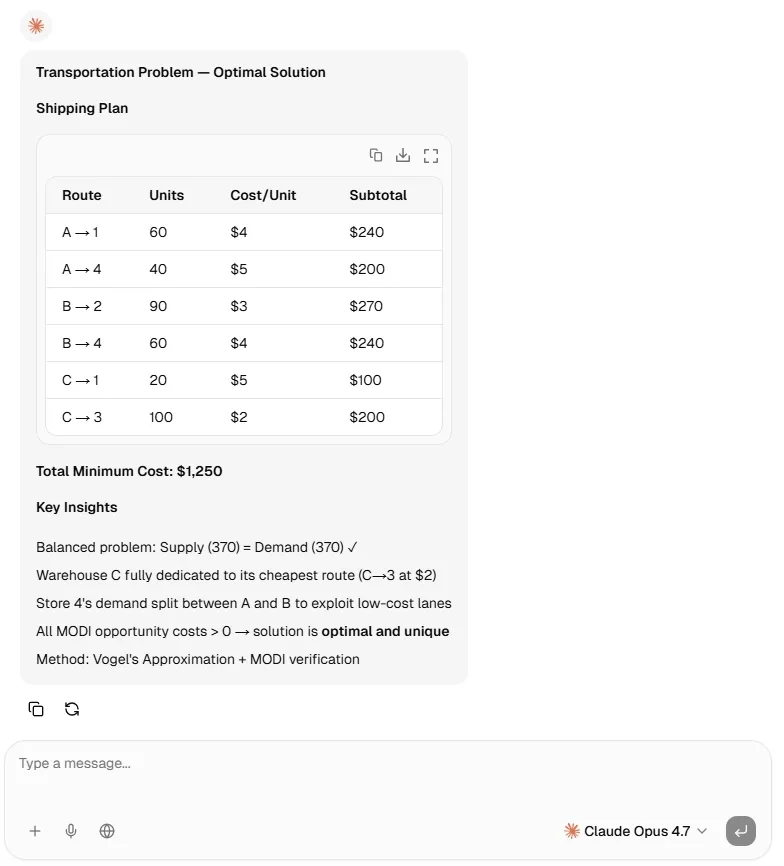
Claude Opus 4.6 applied Vogel's followed by the MODI method, and successfully output the true optimal cost of $1,250, with a perfectly acceptable allocation.
Kimi K2.6 Reasoning Test 🧠
Claude Opus 4.7 Reasoning Test 🧠
How to Access Kimi K2.6
To use Kimi K2.6, you can find it available through several channels, depending on whether you want a simple chat experience or a more flexible multi-model setup.
Here are the main ways to use it:
- Website and app: Use Kimi directly through its web interface or official mobile app
- Moonshot AI API: Integrate Kimi K2.6 into your own tools, products, or workflows
- Kimi Code CLI and IDE tools: Access the model in coding environments for developer-focused tasks
- Hugging Face: Use the model weights for self-hosting and custom deployment
- Cloudflare Workers AI: Reportedly available for serverless AI deployment
- Lorka AI: Use Kimi K2.6 in an all-in-one environment and combine it with other top LLMs like Claude Opus, DeepSeek, GPT, and more
Pricing should always be checked directly through Moonshot AI before publishing, since API costs can change. For users who want to compare models rather than manage separate subscriptions and interfaces, Lorka offers the clearest practical advantage.
Try Kimi K2.6 in Lorka AI
Use Kimi K2.6 inside Lorka AI and compare it with other top models like Claude, GPT, DeepSeek, and more in one place.
Try Kimi K2.6 in Lorka AIKimi K2.6 Pricing
The Kimi K2.6 API access price is:
- Input: $0.95 per million tokens
- Output: $4.00 per million tokens
The context window size is 262,144 tokens.
The Bigger Picture
Kimi K2.6 shows how quickly open-weight frontier models are catching up to closed-source leaders, especially in coding, tool use, and long-horizon agent workflows. It is not better at everything, but it is strong enough to be part of the serious comparison now, not just the budget alternative.
Western labs face rising pressure. While premium models excel in multimodal performance, polish, and enterprise reliability, they must now justify higher prices with a superior overall product, as open models are no longer inherently second-tier.
FAQs
Kimi K2.6 is a 1-trillion-parameter open-weight Mixture-of-Experts model released by Moonshot AI on April 20, 2026. It has 32 billion active parameters per forward pass, a 256K context window, and is perfect and optimized for long-horizon agentic tasks.
