
TL;DR: The Core Building Blocks of LLMs
Token Rules of Thumb: The Essential Cheat Sheet
• 1 token ≈ 4 characters of English text
• 1 token ≈ ¾ of a word (100 tokens ≈ 75 English words)
• 1,000 tokens ≈ , 750 words ≈ , roughly 3 pages of standard text
• Spaces, punctuation, and formatting all count as tokens
• Non-English text is tokenized less efficiently; the same idea costs more tokens
• Output tokens (AI responses) are typically priced higher than input tokens (your prompt)
• Context window = the total token budget for one conversation (input + output combined)
What Is an AI Token? Definition and Meaning
An AI token is a piece of data, a syllable, a word, a character, or a short subword fragment that a large language model uses as its basic unit of processing. When you send a message to an AI model, it does not read your text as a continuous stream of characters the way a human would.
It first converts your text into a sequence of tokens, processes those tokens mathematically, and generates a response as a new sequence of tokens that is then converted back into readable text.
A useful analogy: if language is a molecule, tokens are its atoms. Just as chemistry describes matter not in terms of objects but in terms of atomic units, AI describes language not in terms of words but in terms of tokens.
Why AI Doesn’t Read Text the Way Humans Do
Humans read in words and sentences. We understand “cat” as a single unit of meaning, and we recognize “running” as a word even though we know it comes from "run". AI language models do neither of these things natively. They operate purely on numerical representations.
Before any text can be processed by a model, a component called the tokenizer converts the raw text into a list of integers. Each integer corresponds to a specific token in the model’s vocabulary, a lookup dictionary that maps every known text fragment to a unique ID number.
The model processes these numbers through its neural network layers and produces a sequence of output number IDs, which are then decoded back into readable text.
This numerical pipeline is why tokenization matters practically: the model has no concept of a “word” as a unit. It only knows the tokens in its vocabulary. Common short words like "cat", "run", and “the” often map to a single token.
Longer, rarer, or compound words, like “unforgettable” or “tokenization”, are typically split into multiple tokens. You can explore this directly using OpenAI’s tokenizer tool, which shows exactly how any input text is broken down by GPT models.
You can refer to the following diagram to understand how text flows through the tokenization pipeline:
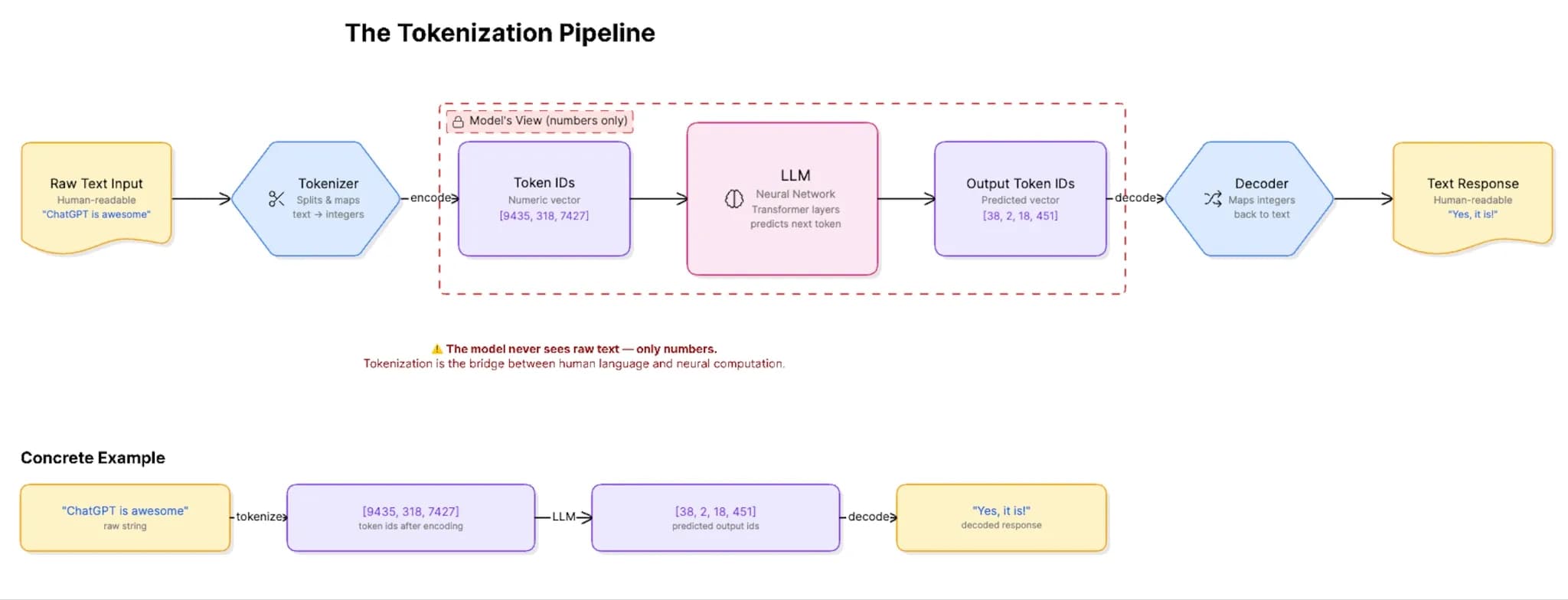
How Tokenization in AI Works
Modern LLMs use a tokenization algorithm called Byte Pair Encoding (BPE) or a variant of it. BPE builds its vocabulary by starting with individual characters and repeatedly merging the most frequently co-occurring pairs into single tokens.
The result is a vocabulary of 30,000 to 100,000+ tokens that efficiently represents common text patterns while still being able to handle any input by falling back to character-level or byte-level tokens for unknown sequences.
The practical consequences:
-
Common and very short words tend to map to a single token.
-
Longer, rarer, or technical words are split into multiple sub-word tokens.
-
Proper nouns, brand names, and words from low-resource languages are particularly expensive, each can take several tokens to represent.
What Is a Token in Generative AI With Examples (Visualizing the Split)
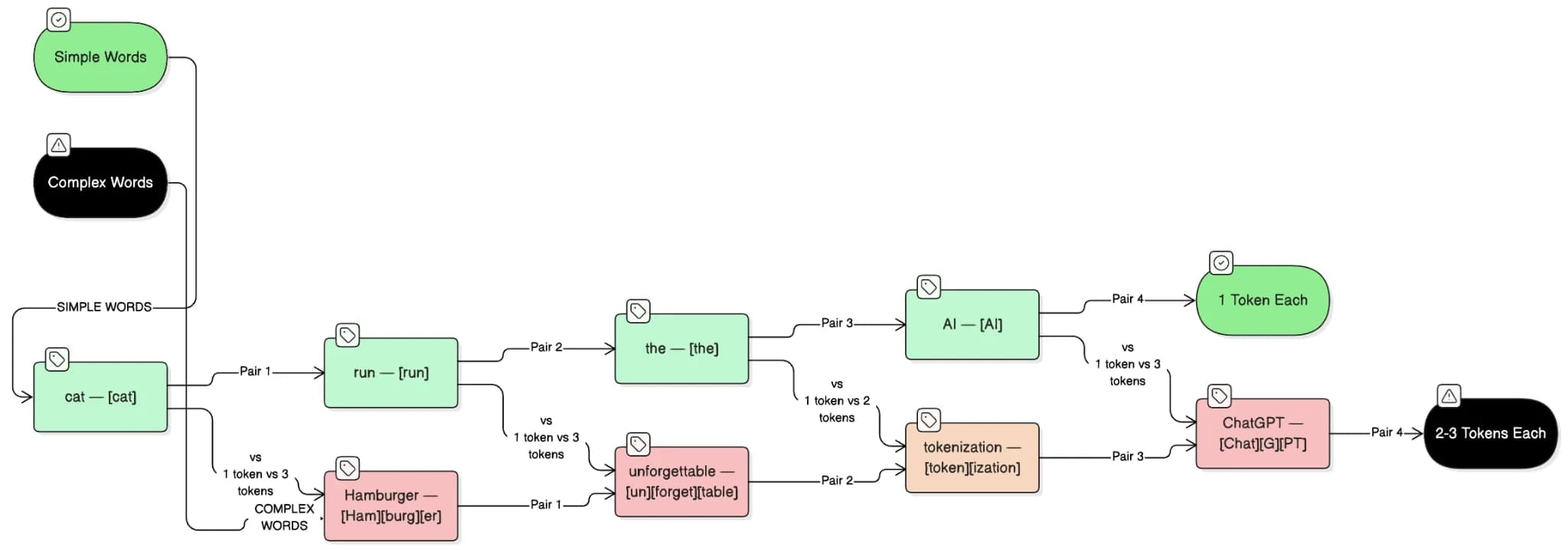
The most effective way to understand tokenization is to see it in action. The following examples show exactly how the same sentence produces different token counts depending on the words used.
Example 1: Common, short English words (efficient tokenization):
🤖 Token Example 1: Simple English sentence
Original text: The cat sat on the mat.
Tokenized: [The][ cat][ sat][ on][ the][ mat][.]
Token count: 7 tokens
ℹ Common short words = 1 token each. Total: 7 tokens for 6 words. Highly efficient.
Example 2: A complex technical word split across multiple tokens:
🤖 Token Example 2: A longer, technical word
Original text: Tokenization is fundamental to LLMs.
Tokenized: [Token][ization][ is][ fund][amental][ to][ LL][Ms][.]
Token count: 9 tokens
ℹ Notice: 'Tokenization' alone costs 2 tokens. 'Fundamental' costs 2 tokens. 'LLMs' cost 2 tokens. Total: 9 tokens for 5 words.
Example 3: The famous example: ChatGPT’s own name:
🤖 Token Example 3: Brand names and compound words
Original text: ChatGPT is awesome.
Tokenized: [Chat][G][PT][ is][ awesome][.]
Token count: 6 tokens
ℹ ChatGPT splits into 3 tokens despite being one word. Brand names, technical terms, and proper nouns are among the least efficient token users.
Note: Exact token splits vary by model and tokenizer version; these examples illustrate the principle, not a fixed result.
You can refer to the following infographic to see a visual side-by-side of how simple vs. complex words compare in token cost:
Why Do AI Tokens Matter? The “Currency” of Generative AI
Tokens are not just a technical implementation detail. They are the unit of account for everything that matters practically about using AI: how much memory the model has, how much your API calls cost, and how long the model can sustain a coherent conversation.
Context Windows: The Memory Limit of Your AI
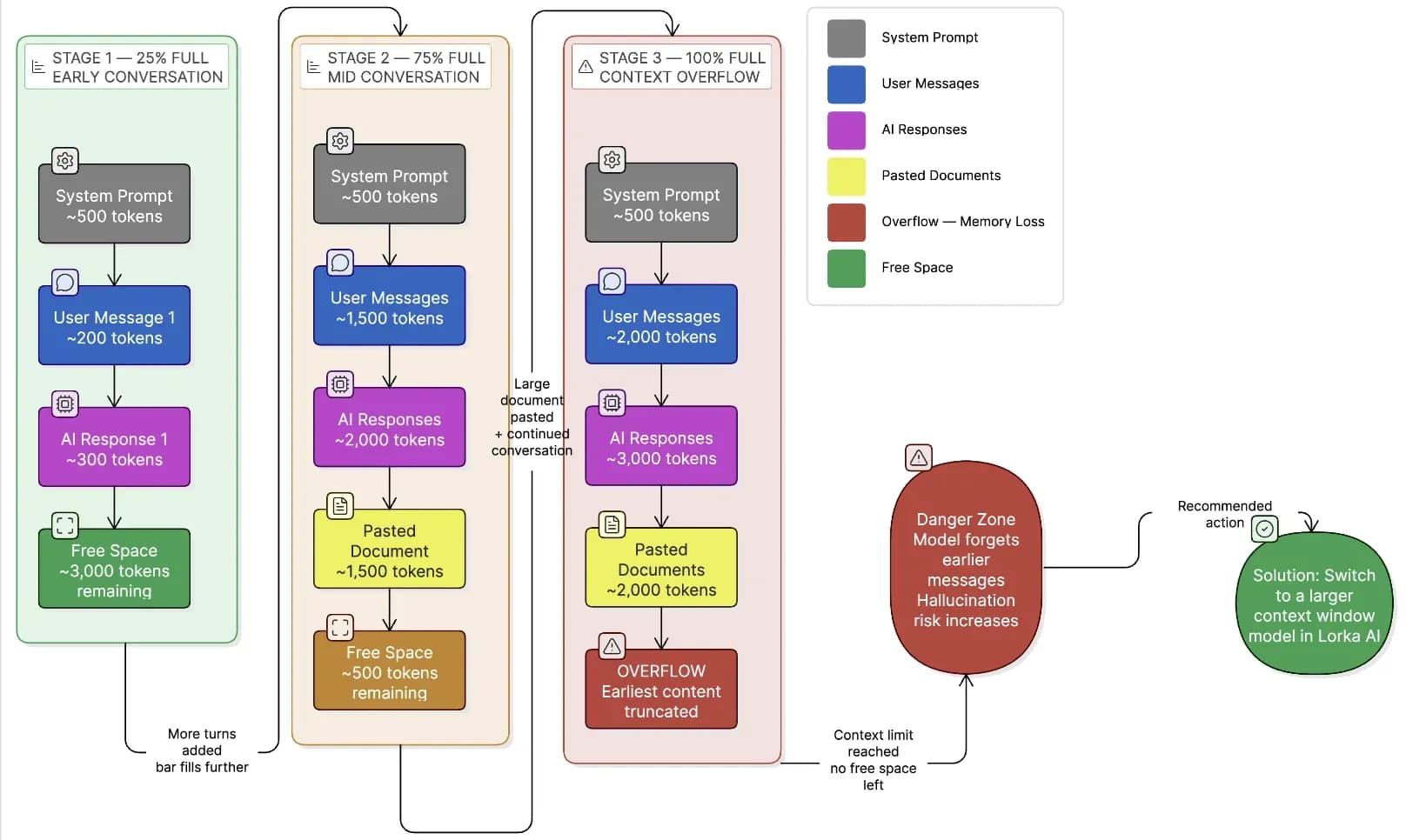
Every language model has a context window, the maximum number of tokens it can hold in working memory at one time. This includes your entire conversation history: every message you have sent, every response the model has generated, any documents you have pasted in, and any system instructions.
When the total token count of a conversation exceeds the context window limit, the model begins to “forget” earlier parts of the conversation.
Context window sizes have grown dramatically in recent years and continue to expand:
| Model | Context Window | Practical Implication |
|---|---|---|
| Claude Sonnet 4.6 | 1M tokens (API) / 500,000 tokens (Web) | Handles approximately 150,000 words, roughly 600 pages of text, in a single conversation |
| GPT-5.5 | 1M tokens (API) / 400,000 tokens (Codex) | Processes extremely long documents, codebases, or extended multi-turn research sessions |
| Gemini 3.1 Pro | 1,048,576 tokens (~1M+) | Analyzes entire books, large repositories, or hours of transcripts in one pass |
| Standard/Older Models | 4,000–16,000 tokens | It hits limits quickly on long documents or multi-step workflows; context loss is common |
When you hit a context window limit, the model does not warn you clearly; it simply starts ignoring or misremembering earlier parts of the conversation. This is one of the most common sources of AI output degradation in long sessions.
Switching to a model with a larger context window, like Claude Sonnet 4.6's 1M token window, Gemini 3.1 Pro’s 1M+ token window or GPT-5’s 400k window, is the correct solution, not repeating the context.
You can refer to the following diagram to visualize how a context window fills during a conversation:
Pricing and Billing: Input Tokens vs. Output Tokens
Every commercial AI API, including OpenAI, Anthropic, and Google, bills usage in tokens, not words or requests. And critically, input tokens (the tokens in your prompt) and output tokens (the tokens in the model’s response) are priced separately, with output tokens typically costing significantly more, because generating text requires far more compute than reading it.
| Token Type | What It Is | Pricing Tier | Example |
|---|---|---|---|
| Input Tokens | All tokens the model reads: your prompt, conversation history, system instructions, pasted documents | Lower cost, reading requires less computing than writing | A 500-word prompt = approximately 667 input tokens |
| Output Tokens | All tokens the model generates: its full response, including reasoning steps in chain-of-thought models | Higher cost, generation is computationally intensive | A 300-word response = approximately 400 output tokens |
| Cached Tokens | Repeated input content that some providers cache and charge at a discount (e.g., a repeated system prompt) | Heavily discounted, often 50–90% cheaper than standard input | The same system prompt is reused across 100 API calls |
The industry standard in 2026 is to price per 1 million tokens (MTok). Rather than tracking exact prices for each model here, they update frequently, check OpenAI’s official pricing page and Anthropic’s documentation for current per-MTOK rates. The architectural principle, input cheaper than output, is stable across all providers.
LLM Tokens: Are All Tokens the Same?
No, all tokens are not the same. Each major AI provider trains and maintains its own tokenizer with its own vocabulary. This means the same text can produce different token counts depending on which model you use.
It also means that the “1 token ≈ 4 characters” rule of thumb applies specifically to English text in modern tokenizers; other languages are a different story.
OpenAI Tokens vs. Claude and Gemini Models
OpenAI uses a tokenizer called Tiktoken for its GPT model family. Anthropic uses its own tokenizer for Claude. Google uses a SentencePiece-based tokenizer for Gemini. While all three are designed around similar BPE-style principles, their vocabularies differ, meaning that a prompt costing 500 tokens in GPT-5 might cost 480 tokens in Claude or 520 in Gemini.
For most practical purposes, these differences are small enough to ignore for individual prompts. They become relevant when you are processing large volumes of text through an API or when precise cost modeling matters for a production system. In those cases, use each provider’s official tokenizer to measure your actual input cost before committing to a workflow.
How Non-English Languages Consume More Tokens (The “Token Tax”)
Modern tokenizers are trained primarily on English text. As a result, English achieves the highest tokenization efficiency: roughly 1 token per 4 characters.
For other languages, particularly those using non-Latin scripts, Arabic, Chinese, Japanese, Korean, Hindi, and many others, the same semantic content costs significantly more tokens to represent. This is known informally as the Token Tax.
| Language | Approx. Characters per Token | Token Efficiency vs. English | Practical Impact |
|---|---|---|---|
| English | ~4 characters | Baseline (100%) | Most cost-efficient language for AI workflows |
| Spanish / French | ~3.5 characters | ~88% as efficient | Minor cost increase for the same content |
| Russian / Greek | ~2–3 characters | ~60–75% as efficient | Noticeably higher costs for large documents |
| Arabic / Hebrew | ~1.5–2 characters | ~40–50% as efficient | Significant cost premium; context fills faster |
| Chinese / Japanese / Korean | ~1–1.5 characters | ~25–40% as efficient | The same document may cost 2–3x more tokens than English |
The practical implication: if you are building multilingual AI workflows or processing large volumes of non-English text, the token tax is a high-cost and context-window variable. Budget 2 to 3 times more tokens for the same semantic content in affected languages.
How to Optimize Token Usage in Lorka AI
Lorka AI is a single workspace for working across models (not an API) so you can compare and switch models without managing separate developer accounts. The biggest practical challenge with tokens is not understanding them conceptually; it is managing them across different models in real workflows. GPT-5 has a 400k context window, Claude Sonnet 4.6 has 1M tokens via API, and Gemini 3.1 Pro extends to 1M+.
Choosing the right model for your token volume requires knowing which model you are on, how much context you have consumed, and when switching makes sense, all of which is friction-heavy when you are managing multiple tabs.
Switching Models Seamlessly for Cost and Context Efficiency
Lorka AI is built specifically for this problem. It provides a single workspace where you can run the same prompt across Claude Sonnet 4.6, GPT-5, and Gemini 3.1 Pro simultaneously; compare outputs side by side; and switch to a model with a larger context window the moment you start hitting limits, without losing your conversation context or rebuilding your prompt.
This is the practical solution to the three most common token-related problems:
| Problem | What Happens | Lorka AI Solution |
|---|---|---|
| Context window overflow | The model starts forgetting earlier conversations; outputs become incoherent or irrelevant | Switch instantly to Gemini 3.1 Pro (1M+ tokens) without re-entering context |
| Unexpectedly high API costs | Long documents and complex prompts consume far more tokens than estimated | Compare per-model token costs side by side before committing to a workflow |
| Token Tax on multilingual content | Non-English content exhausts context windows 2–3x faster than expected | Route multilingual tasks to the model with the largest context window for your language |
For writers, analysts, and developers who work with long documents, multi-step research, or large codebases, having access to Gemini’s 1M-token window through Lorka AI is the difference between a workflow that works and one that breaks mid-task.
Optimize Long AI Workflows in Lorka AI
Compare GPT, Claude, and Gemini in one workspace, manage large context windows, and keep long documents moving without rebuilding your prompts.
Try Lorka AI for Long Context WorkflowsConclusion: Tokens Are the Foundation of AI Fluency
Understanding tokens transforms how you use AI.
-
It explains why a long-pasted document causes a model to “forget” earlier instructions (context window limits).
-
It explains why your API bill is higher than expected (token-heavy formatting and long outputs).
-
It explains why the same prompt costs more in one language than another (the Token Tax).
-
It tells you exactly which model to choose when your task exceeds a standard context window.
Tokens are the atoms of language as AI understands it. Mastering them, how they are counted, how they are priced, and how to manage them across models are the foundational skills that separate competent AI users from fluent ones.
If you work with large documents, multilingual content, or long research sessions, use Lorka AI to compare models by token efficiency and context window size in a single workspace, and route to the right model the moment you need it.
FAQs About AI Tokens
Approximately 750 words in English. The standard rule of thumb is that 1 token equals roughly three-quarters of a word, or equivalently, 100 tokens equal about 75 words.
A typical 500-word blog introduction is approximately 667 tokens. A 10-page business report of around 2,500 words is approximately 3,333 tokens. These estimates apply to standard English prose; technical content with many long or compound words will be slightly more token-expensive.
