
Key Takeaways⭐
- AI hallucinations occur when a large language model generates information that appears accurate but is actually incorrect or fabricated.
- This happens because models predict the next word based on probability, not by verifying facts from a reliable source.
- Hallucinations are a natural outcome of how language models function, not simply a flaw to be eliminated.
- The severity of hallucinations depends on the use case, low-risk in creative tasks, but critical in high-stakes domains like law or healthcare.
AI hallucinations are something that many people misunderstand about language models. They are not necessarily a problem that needs to be fixed, but rather a natural part of how these systems operate.
This is crucial for anyone who is working with AI hallucinations and generative AI and wants to make sure that AI hallucinations do not cause any issues.
Understanding What an AI Hallucination Is
Imagine asking an AI for a legal case, and it confidently cites a completely fake ruling that never existed. This has already happened in real-world scenarios—and later in this article, we’ll explain how to prevent it.
An AI hallucination happens when a large language model generates content that is false, fabricated, or nonsensical, even though it sounds confident and well-structured.
This issue is getting a lot of attention, especially as generative AI is used in high-stakes areas like legal analysis, healthcare, and financial decision-making.
The term “hallucination” comes from psychology, where it refers to perceiving something that isn’t real. In AI, the concept is similar: the model identifies patterns from its training data and produces responses that fit those patterns, even when the underlying facts are incorrect.
Because of this, hallucinations can be risky. In fields like law, medicine, or finance, incorrect outputs can lead to misinformation, flawed decisions, and real-world consequences.
The standard definition vs. technical reality
People usually say that AI hallucinations are when the AI lies or makes things up. That is not really what is going on inside the artificial intelligence model.
A better description would be when the model makes a mistake because it is trying to complete a pattern based on what it learned from the data it was trained on to give actual, verified information.
This results in the AI saying something that sounds right but is actually wrong.
We need to know the difference because this will change the way we think about solving the problem.
If the AI were just lying, we would think that it should know better.
The problem is actually because of how the AI is designed to generate text. To fix this, we need to change how we build systems around the AI rather than expecting the AI to work like a database.
Why the term "hallucination" is not always right
The word "hallucination" makes it sound like the AI is doing something broken.
Artificial intelligence is just doing what it was made to do. It comes up with a part of a text based on what it has learned from the things it was taught.
For example, if someone asks, "What was the final score of the 1998 FIFA World Cup final?" The artificial intelligence might say, "France defeated Brazil 3-0". " This is actually correct. Artificial intelligence knew this because it saw this information a lot in the things it was taught.
Now consider another question: 'What was the final score of the 2026 FIFA World Cup final?' " If the artificial intelligence were taught with information from before the tournament happened, it might still give an answer that sounds good. Like the sentence "Argentina defeated France 2-1".
Artificial intelligence is coming up with text based on what it has learned. Big teams such as Argentina and France often make it to the finals. Artificial intelligence knows this because it learned about the FIFA World Cup and how big teams, like Argentina and France, often do well.
The agent is simply doing its job, which is to create text based on what it has learned. It is generating text based on patterns.
The model is not giving information about the 2026 result. It just can't tell the difference between completing a pattern and finding a fact because it does the same thing for both.
This is why AI making things up is actually how these systems work, not a mistake that can be fixed.
What's really going on inside a large language model?
To know why AI makes things up, it helps to look at how big language models make text.
Unlike software that follows clear rules or looks up organized data, LLMs work in a totally different way, based on chance and finding patterns.
Probabilistic Generation: The Math of Next-Token Prediction
At their core, modern language models are next-token prediction engines.
When you give a model a prompt, the model does not think about the answer, as a being does. The model goes through the following process:
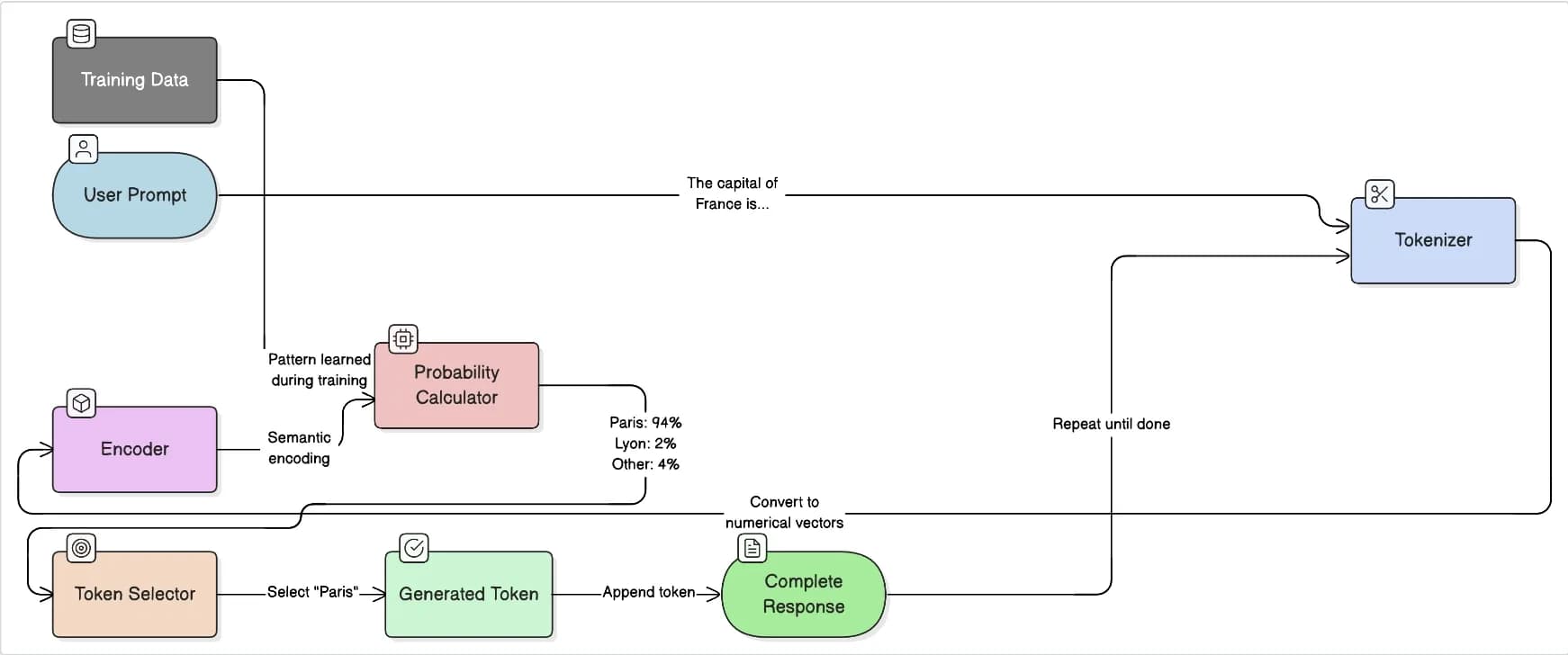
Step 1: The model breaks the text into parts like words or pieces of words.
Step 2: The model changes these parts into numbers that have meaning.
Step 3: The model figures out which word is most likely to come next.
Step 4: The model picks the word based on how likely it is to occur and some other settings.
Step 5: The model adds the word to the text and does the same thing again until it is finished.
Let me show you an example of how the model works.
If you ask the model, "The capital of France is...", the model thinks about what word comes next. The model looks at the words the model has learned and tries to figure out which one is most likely to come after "The capital of France".
The model calculates probabilities for the next token:
| Token | Probability |
|---|---|
| Paris | 0.94 |
| Lyon | 0.02 |
| London | 0.01 |
| Rome | 0.01 |
| (other tokens) | 0.02 |
In this situation, the city "Paris" is very likely to be the answer with a high chance of about 94 percent, so the model is pretty sure it is correct.
What if we ask a more confusing question:
Input prompt: "The most effective treatment for advanced neural pathway degeneration is."
This is a very specific medical question, so the information the model learned may have some disagreements, not many examples, or not enough background information. The chances of each answer might look like this:
| Token | Probability |
|---|---|
| experimental | 0.15 |
| targeted | 0.12 |
| combination | 0.11 |
| pharmaceutical | 0.09 |
| (200+ other tokens) | 0.53 |
Notice that no single token dominates. The model must still generate a response, so it selects from this flatter distribution. This is where things can go wrong with these models. They can start making things up and using medical words that sound good. The truth is, they do not really know what they are talking about.
The model might say something like "The best way to treat neural pathway degeneration is to use special medicines that protect the nerves along with other treatments that target the problem."
This sentence sounds like it was written by a doctor. It is grammatically correct and uses the right medical words. It even sounds like it knows what it is talking about. The problem is, this treatment might not actually work, or it might not even be real. The model is just making it up because it sounds good.
The neural pathway degeneration treatment that the model talks about might not be supported by medical evidence.
The difference between grounding and training data
One key thing to understand about AI hallucination is the difference between grounding and training data.
Training Data: This is the collection of text that the model learns from when it's being trained. It includes billions of documents, websites, books, and code. Once the model has learned from this data, it gets. Becomes part of how the model works.
Grounding: This is the real-time information that the model gets when it's being used, like when it's trying to answer a question. This information is usually provided through tools or by searching for the latest facts.
Think about it like this:
- Training data is what the model knows from the start.
- Grounding is what the model learns at the moment.
This difference is really important.
| Scenario | Information Source | Reliability |
|---|---|---|
| No grounding | Training data only (frozen) | Moderate to low for recent facts |
| RAG grounding | Retrieved documents + training data | High for included documents |
| Tool grounding | Live API calls, databases, search | High for current information |
When a model works with training data, it can only give answers based on what it learned from that data.
This causes some issues:
Problem 1: Knowledge cutoff
The model does not know about things that happened after its training data was collected.
Problem 2: Ambiguity resolution When the training data has information, the model still has to give an answer, and it might make up details to fit the pattern.
Problem 3: topics For subjects that are not common, the model does not have many examples and might guess wrong.
Grounding solves these problems by giving the model up-to-date information right in the question.
For example, if you ask a model the following:
"What are the system requirements for the version of Adobe Premiere Pro?"
Without grounding, the model's answer is based on old or general training data. With grounding, the system gets the specs from Adobe's official info and includes them in the question. The model uses this information to give a better answer about Adobe Premiere Pro system requirements. This way, the model provides accurate information about Adobe Premiere Pro.
The model can now generate a response grounded in verified, current information rather than relying solely on probabilistic pattern completion.
This approach dramatically reduces the AI hallucination rate for factual questions.
Pattern completion: why AI prioritizes "looking correct" over "being correct"
The thing that really is unexpected about artificial intelligence behavior is that these systems are made to produce text that sounds good, not text that's actually true.
This difference is really important.
Artificial intelligence learns by guessing what word comes next in a sentence from the things it was taught.
The goal of the training is simple: make it more likely that artificial intelligence guesses the word that comes next.
Nowhere in this process does the model learn a concept of "truth" or "factual accuracy" in the way humans understand it.
Instead, it learns:
- Grammar and syntax
- Common phrase structures
- Domain-specific terminology
- Statistical associations between concepts
Consider this example:
If the training data has 1,000 documents that say "Python is a programming language" and 5 documents that say "Python is a database system", then the model will mostly get it right. It will learn that Python is a programming language, not a database system, because it sees "Python is a programming language" many more times.
But if the training data contains the following:
- 50 documents discussing "quantum entanglement in distributed databases".
- 30 documents about "blockchain-based neural optimization."
- 20 documents on other speculative or theoretical concepts
The model will figure out that these phrases are things that people say a lot, even if they are not really true or are just ideas.
When you ask the model, "Explain how quantum entanglement improves distributed database performance", the model will come up with an answer that:
- Uses correct technical vocabulary
- Follows logical sentence structure
- Sounds authoritative
But the content may be entirely fabricated because the model is simply completing a pattern it observed in speculative or science-fiction contexts.
This is why LLM hallucination detection has become a critical field of research for organizations deploying these systems in production.
Common Causes of AI Hallucinations
AI hallucinations are something that large language models do naturally. Some things make them happen a lot more often. If we know what these things are, we can make systems that do not have many AI hallucination problems.
Training data gaps and biases
The training data that we use to teach a model is really important. It affects how often the model makes things up.
Cause 1: not informed about special subjects❌
For example, if a model learned from things people post on the web but did not learn much about medical books, it might have trouble with medical words. When we ask, "What is the right amount of medicine that doctors can give to people?"
The model might make up an answer that sounds good, but it is not really true. It does this because it is using patterns from medicines, not real information about the new one.
Cause 2: not knowing about new things❌
All models have a date when they stopped learning, which is the last day of their training. If we ask about something that happened after that date, the model has to make a guess. It is often wrong.
Example:
The model stopped learning in January 2025. We ask, "What new things were added to the iOS 19 release in March 2025?" The model might make up features based on old iOS releases instead of saying it does not know.
Cause 3: confusing information in training data❌
The internet has a lot of information that does not match old news and things that people guess are true. When a model sees information that does not match, it still has to give an answer, so it might say things that are true and not true at the same time.
Training data quality vs hallucination rate
| Training Data Characteristic | Impact on Hallucination Rate |
|---|---|
| High-quality, good sources | Low hallucination rate |
| Mixed-quality web scraping | Moderate hallucination rate |
| Specialized domain with limited data | High hallucination rate |
| Outdated or conflicting information | High hallucination rate |
This is why many organizations that build domain-AI systems choose to fine-tune models on carefully selected datasets instead of just using general models.
High Temperature Settings and Randomness: Another factor in AI making things up is the temperature setting. It controls how random the model is when picking the word.
Temperature is a setting that affects how predictable or creative the model's answers are.
When the model generates the word, it does not always pick the most likely option. It sometimes chooses a likely one to make the output more interesting.
The model uses randomness to come up with ideas. This randomness is controlled by the temperature setting. Many AI systems use a temperature to make the output more varied.
Sometimes this can make the output less accurate.
| Temperature Setting | Behavior | Hallucination Risk |
|---|---|---|
| 0.0 - 0.3 | Highly deterministic, conservative | Lower risk |
| 0.4 - 0.7 | Balanced creativity and consistency | Moderate risk |
| 0.8 - 1.0 | Creative, varied, unpredictable | Higher risk |
| >1.0 | Highly random, experimental | Very high risk |
Example of temperature impact 🌡️
Prompt: “List three major cities in Germany.”
Temperature = 0.2
Response: “Berlin, Munich, Hamburg”
(High-probability, factually safe)
Temperature = 0.9
Response: “Berlin, Frankfurt, Heidelberg”
(Still possible. Heidelberg is a lot smaller than Hamburg or Munich. That’s not an entirely accurate answer.)
Temperature = 1.5
Response: “Berlin, Rothenburg, Nuremberg”
When accuracy is super important, in law, medicine, or finance, using temperature settings can help reduce mistakes.
However, for creative tasks such as the following:
- Brainstorming
- Creative writing
- Generating marketing copy
Higher temperature settings can be a thing because they make things more interesting and varied, even if that means they are not always completely accurate.
The problem of not having internet access at the time (this is also called 'grounding issues'):
One of the reasons things do not make sense is that the internet is not working in real time. This is a cause of false information, which people call hallucinations.
When models operate purely from training data, they cannot:
- Access current information
- Verify facts against authoritative sources
- Update their knowledge based on what's happening now
Consider this situation:
User question: "What is the current stock price of Tesla?"
Without internet access: If the system does not have access to the internet, it might come up with a number that seems okay based on what happened in the past, but the Tesla stock price it gives will probably be wrong.
The system needs to know the information about Tesla to give a correct answer.
With internet access (via tool use): The model can query a financial API and return the actual current price.
This is a problem, and that is why a lot of production artificial intelligence systems use one of the following architectures:
| Architecture Type | How It Works | Hallucination Risk |
|---|---|---|
| Pure LLM | The model is generated from training data only | High for facts, dates, and current events |
| RAG (Retrieval-Augmented Generation) | Retrieves documents first, then generates | Low for included documents |
| Tool-augmented | The model calls APIs, databases, or search engines | Very low for verifiable facts |
| Hybrid | Combines RAG + tools + LLM reasoning | Lowest overall risk |
For organizations that are worried about the AI hallucination rate in their systems, using RAG or tool-augmented architectures is one of the best ways to deal with the problem.
Real-World AI Hallucination Examples
It is useful to understand what AI hallucination is. Looking at specific examples of AI hallucination, in the real world, really helps to show what kind of impact it can have.
The following cases represent actual categories of hallucinations that have occurred in production systems and research evaluations.
Fabricated Citations in Legal and Academic Research
One of the most serious manifestations of AI hallucinations occurs in legal and academic contexts, where citations to nonexistent sources can have significant consequences.
Example 1 is about making up legal cases.
In the year 2023, there were some incidents where lawyers used legal papers made by artificial intelligence that talked about court cases that never happened.
For example, a computer program might generate something like this: "As established in Martinez v. Delta Airlines in the year 2019, the precedent supports..." This citation looks like it is formatted correctly; it has a case name that sounds real. It talks about a real company. The truth is, this case never existed. So why does this happen to the briefs made by artificial intelligence?
The reason is that the computer program learned how to make citations from the data it was trained on. The model knows what a legal citation should look like:
- Case name format: Plaintiff v. Defendant
- Year in parentheses
- Citation context
When asked to support a legal argument, the model generates text that matches this pattern, even when no such case exists.
Example 2: Academic paper hallucinations Similar issues occur in academic research.
A model might generate:
“Smith and the other people who worked with him said that in the year 2022, they found out that variable X and variable Y are related in a way. They were able to figure this out because the results of their test were very unlikely to happen by chance, which is shown by the letter p being less than 0.05 when they looked at variable X and variable Y.”
The citation format is correct, the statistical notation is appropriate, but the paper may not exist.
Impact for professionals:
| Domain | Risk Level | Consequence |
|---|---|---|
| Legal practice | Critical | Sanctions, malpractice claims |
| Academic research | High | Retracted papers, reputation damage |
| Journalism | High | Published misinformation |
| Business analysis | Moderate | Poor strategic decisions |
This is why AI hallucination detection methods have become essential for any system used in professional research contexts.
Best Practice ℹ️
Double-check citations made by AI against trusted sources, like Google Scholar, Westlaw, or LexisNexis.
Non-existent APIs and Coding Functions
Another common category of hallucinations occurs in code generation, where models invent API endpoints, library functions, or configuration options that don't exist.
The AI Hallucination Problem: Why It Matters for Workflows
Hallucinations are something that people have written about a lot. How they affect things depends on what you are using them for and where you are using them.
It is helpful for organizations to know where hallucinations can cause problems so they can use their resources to detect and stop them in the right places.
Risks for Marketers and Data Analysts
Marketing and analytics teams are using AI tools more to make content, summarize data and get insights from it. These tools can help people get a lot done. They also bring some specific risks related to AI hallucinations.
Risk 1: Made-up performance numbers: Let us say a marketing manager asks an AI system, "Tell me how our email campaign did in the quarter of 2026." If the AI system does not have access to the analytics and tries to come up with an answer from what it remembers or a little bit of information, it might say something like:
"Your email campaigns in the first quarter of 2026 had an open rate of 24 percent and a click-through rate of 3.1 percent, which is 15 percent better than the last quarter of 2025."
These numbers might sound like they could be real. If the AI system just made them up, they could lead to making wrong decisions.
Risk 2: Made-up information about competitors: When AI models look at what competitors are doing, they might say things like, "Your main competitor spent 40 percent more on Google Ads in March 2026.
If this is not based on real information about what the competitor is doing, it might just be something the model came up with based on general trends in the industry, rather than something that is actually true about the competitor.
Impact on decision-making:
| Hallucination Type | Business Impact | Mitigation Strategy |
|---|---|---|
| False performance data | Misallocated budget | Always verify against source systems |
| Invented trends | Poor strategic positioning | Use RAG with verified data sources |
| Fabricated competitor actions | Unnecessary reactive changes | Implement competitive intelligence tools |
Implications for Software Developers
For software development teams, artificial intelligence hallucinations are a problem.
Artificial intelligence hallucinations present equally significant challenges for software development teams.
Risk 1: code patterns
When software developers are making security-sensitive code, artificial intelligence hallucinations can cause trouble. Artificial intelligence hallucinations can introduce vulnerabilities when software developers are generating security code.
For example, a model might suggest something that's not safe.
# Authenticate user
def login(username, password): \
query = f"SELECT * FROM users WHERE username='{username}' AND password='{password}'" \
return database.execute(query)
This code has a SQL injection problem. The model might have picked up this pattern from tutorials or bad code examples in its training data. Using it in real-world applications can cause big security issues.
Risk 2: Outdated or non-existent dependencies Models might suggest using libraries or versions that:
- No longer exist
- Have known security vulnerabilities
- Are incompatible with the current environment
Example:
"Install the package like this: pip install deprecated-lib==1.2.3. If this package version was taken down from PyPI because of security problems, developers have supply chain risks.
Risk 3: Wrong guidance on system design
For example, when people ask about system design, models might give suggestions that are not good practice.
Here is a question: "What is the best way to handle database connections in a serverless AWS Lambda function?"
The model might say something like, "You should open a database connection each time the handler function runs and then close it when you're done."
However, that is not right. This approach would create connection pool exhaustion. The correct pattern involves connection reuse across invocations.
Developer workflow protection strategies
| Development Phase | Hallucination Risk | Protection Method |
|---|---|---|
| Code generation | Moderate to High | Automated testing, code review |
| Dependency selection | Moderate | Dependency scanning tools |
| Architecture design | Low to Moderate | Peer review, documentation verification |
| Debugging assistance | Low | Verify suggested fixes work |
How to Detect and Mitigate Hallucinations
Given that hallucinations cannot be eliminated, systems that are being used in production must have ways to find and lessen their impact.
Using different methods together is more effective than using just one.
AI hallucination detection methods
Several methods have emerged for identifying when a model has generated unreliable content. The following diagram shows the hallucination detection and mitigation workflow.
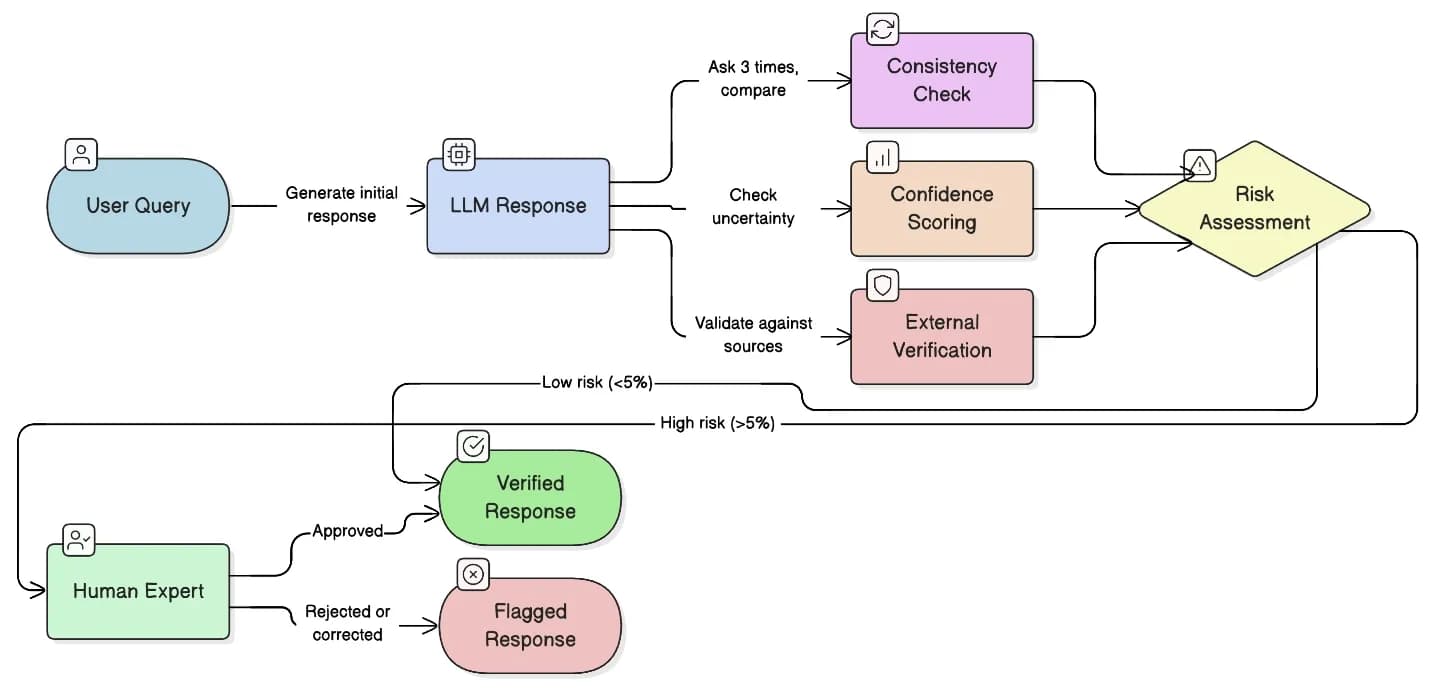
Method 1: Consistency checking When you ask a model the same question many times at low temperature, you can compare the answers.
If the model gives you different answers each time, that means the model does not have a clear idea, and the artificial intelligence model may be making things up.
The artificial intelligence model is basically guessing when it does this, so you have to be careful with the artificial intelligence model's answers.
This method works because:
- Factual information should produce consistent outputs
- Hallucinated content often varies between runs
- Low temperature reduces randomness
Method 2: Confidence scoring Some models now provide confidence scores or uncertainty estimates alongside their outputs. Users can also explicitly request a confidence score in their prompts so they can more easily identify when the model is less certain. While not perfectly reliable, these scores can help flag responses that should undergo additional verification.
| Response Type | Typical Confidence | Action |
|---|---|---|
| Well-grounded facts | >90% | Accept with spot checks |
| Reasonable inferences | 70-90% | Verify key claims |
| Speculative generation | <70% | Require verification |
| High uncertainty | <50% | Reject or escalate to human review |
Method 3: External verification
For critical applications, automated verification against authoritative sources provides the strongest detection method.
Workflow:
- Model generates response
- System extracts factual claims
- Claims are verified against trusted sources
- Unverifiable claims are flagged or removed
Method 4: Human-in-the-loop verification
For the highest-stakes applications, human review remains essential.
Many organizations implement tiered review systems:
| Content Risk Level | Review Strategy |
|---|---|
| Low risk (creative content) | Automated checks only |
| Medium risk (business analysis) | Spot-check verification |
| High risk (legal, medical) | Mandatory human review |
| Critical risk (regulatory) | Multiple expert reviewers |
Best Practices: RAG (Retrieval-Augmented Generation) and Few-Shot Prompting
Beyond detection, several architectural patterns significantly reduce hallucination rates.
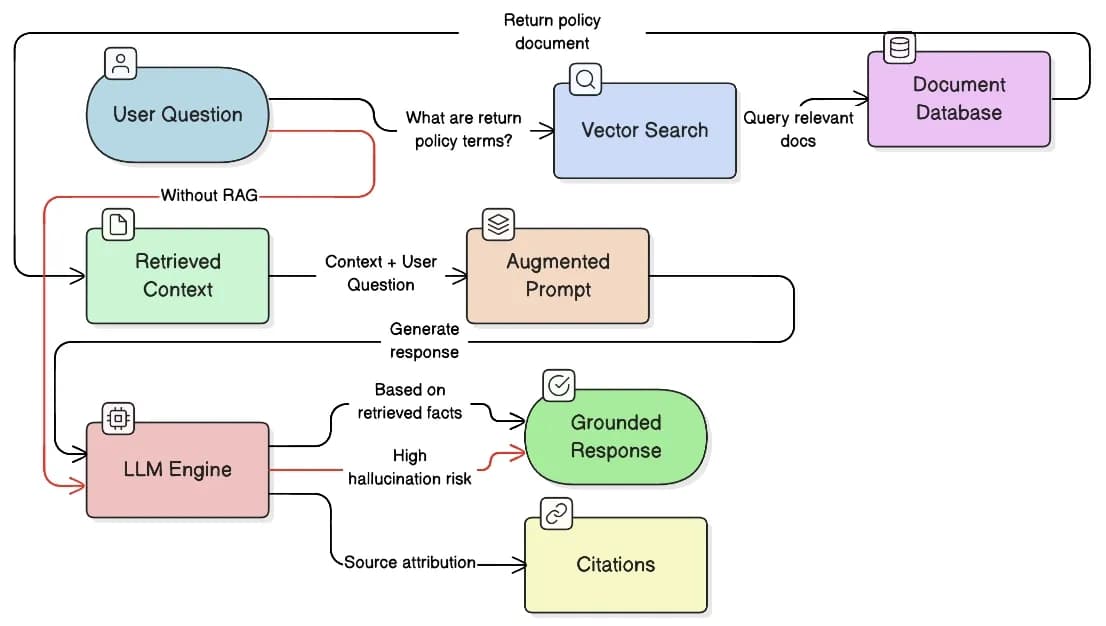
RAG (Retrieval-Augmented Generation) RAG has emerged as one of the most effective hallucination mitigation strategies.
RAG Definition: An AI architecture pattern that retrieves relevant documents before generation, grounding the model's response in verified information.
Benefits:
Organizations can implement RAG using frameworks like LangChain or LlamaIndex, which provide pre-built components for document retrieval and prompt augmentation. The following diagram shows the RAG vs non-RAG architecture:
Few-Shot Prompting When you want to get an answer, it is helpful to give examples of good answers in the question itself.
Standard question that may not give the answer:
"Explain the difference between Python lists and tuples."
Best practice for marketing teams:
Use AI for:
- Drafting initial content
- Generating creative variations
- Summarizing verified data
Always verify:
- Statistical claims
- Competitor intelligence
- Performance metrics
Better question that gives the answer:
Here are examples of good explanations:
Q: What is the difference between RAM and ROM?
A: RAM is the kind of memory that loses its data when the power is turned off. It is used to store the things that the computer is working on right now. ROM is the kind of memory that keeps its data when the power is turned off, and it is used to store the instructions that the computer needs to start up.
Q: What is the difference between Python lists and tuples?
A: [Model generates response following the demonstrated pattern]
The examples help the model:
- Understand the desired format
- See the appropriate level of detail
- Follow accurate technical explanations
This technique is particularly effective for:
- Technical documentation
- Structured data extraction
- Consistent formatting requirements
Chain-of-Thought Prompting
The model has to show how it thinks before it gives the answer, and this helps to cut down on things that are not true.
For developers building AI applications, resources like OpenAI's best practices guide and Google's RAG documentation provide practical implementation guidance.
Conclusion: The Future of Truth in Generative AI
Artificial intelligence hallucinations will keep on being something that language models do for a time. Rather than expecting these systems to achieve perfect factual accuracy through model improvements alone, the field is moving toward architectural solutions that combine LLMs with verification systems.
The thing is, to deal with hallucinations, we have to be realistic about what language models are and what they are supposed to do, and that is to use artificial intelligence models.

Reduce AI Hallucinations with Lorka AI
Compare Claude, GPT, Gemini, and other leading AI models in one place to generate more reliable, better-grounded answers.
Try Lorka AIFAQ: AI Hallucinations
No, AI doesn’t have intent. It doesn’t “decide” to lie. It simply generates what sounds most likely to be correct, even if it’s wrong.
